A computer is used to perform many tasks at the same time. While working on computers, we mostly work on multiple programmes and software at the same time, without any hindrance. To control all the functions, including the disk memory, and to process the operating systems efficiently, the computer uses the model of disk scheduling.
Before we understand what disk scheduling is, let us get clarity on what is disk and how it functions.
A disk in a computer is a magnetic storing drive which is divided into different surfaces. All these surfaces or platters rotate as one unit, and the speed at which it rotates is as high as 5k to 10k RPM.
Further, the exterior of each tray is structured to store data. Each of the track or plate is sub-divided into different blocks. The size of each block is fixed which is used for storing data. In a computer, a block saves the minutest piece of data that is read and processed to the disk in one operation.
There is a read and write head of each and every disk, and this moves in rectilinear motion across the surface of the track. Block numbers are used to request data from the drive, and it is the controller who takes the head to the required track and to have access to the data it then waits till the required block comes under it.
Various requests can come from a request or at the same time, and this is where the role of disk scheduling comes into the picture.
So, what is disk scheduling?
The CPU divides its processing time and divides it in such a manner that no system application face any hindrance. Through disk scheduling, it specifies which task CPU needs to handle first and during which time. Simply put it can be said that the total time of CPU is bifurcated among the various functions and programmes so that each process can process simultaneously at one point in time.
Disk scheduling is scheduling the CPUs time for optimum utilization of the computer.
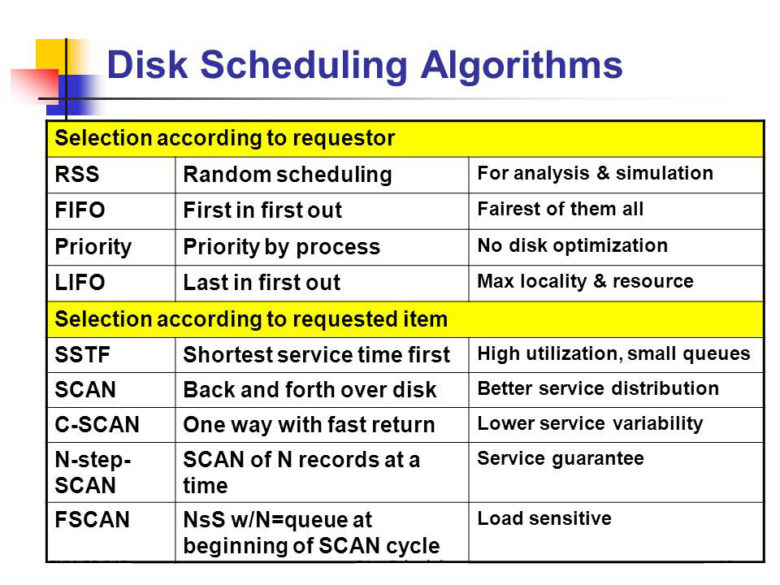
So how is disk scheduling done? What are the various types of disk scheduling?
• First Come First Serve Disk Scheduling
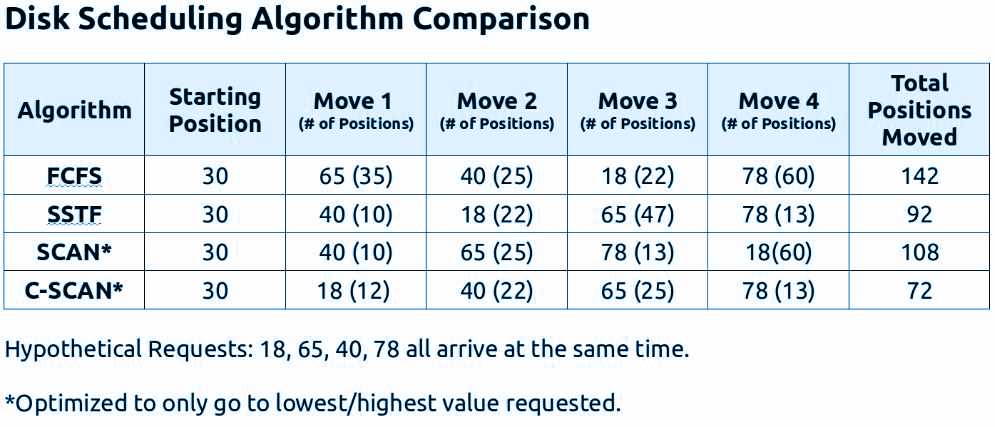
It is also known as FCFC and as the term states the CPU schedules the task in the manner in which a programme is run on the system. The first programme run is expected to occupy the disk space first, and thus it follows sequentially. The number of heads is not considered but the sequential order of processing is followed and the job entered later will be executed in the order they are registered.
• Shortest Seek Time First Disk Scheduling
Also known as SSTF, in this method, the OS searches for the job which requires the shortest time and runs it on the basis of time taken for execution. In this process, the CPU first scans all the tasks and decides by seek time of each of it. It searches for the shortest seek time and schedules the jobs in order to seek time, before proceeding with the one on top.
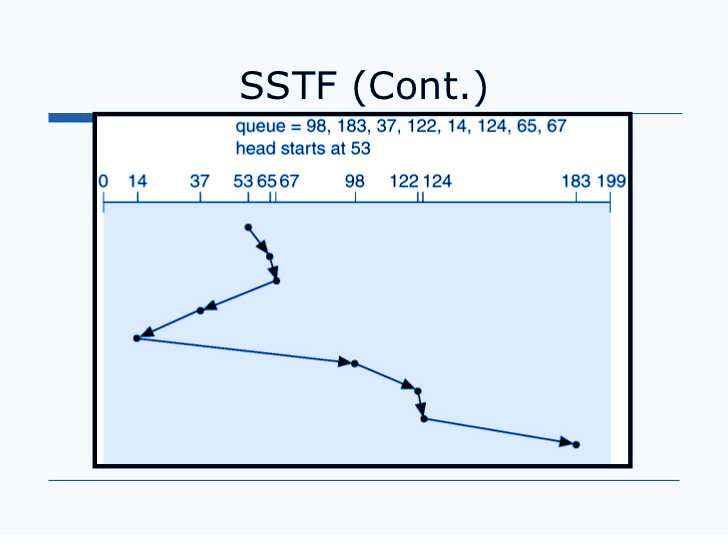
Seek time is the time taken to execute a task, i.e. the time that a drive takes to locate the physical position of a portion of data in the disk.
• Scan Disk Scheduling
In scan disk scheduling the CPU works like an elevator. Just like an elevator moves from bottom to top serving the floors required, this mechanism also works in the same manner, except the fact that it doesn’t run in a vertical direction. Suppose a user enters a request in a space which has already been scanned, it will not get scanned again until its time comes. Imagine you have entered the elevator, which is going upward, on the 4th floor and you want to go to the 3rd floor, will the elevator go down for you? No, it will first go to the top, and then while coming down, it will stop on the 3rd floor.
• Look Disk Scheduling
It is a better version of the scan disk scheduling where it considers the requests if it is scanning in the same direction. In fact, it works in the real sense of an elevator. If the elevator picks someone from the 4th floor and if the person needs to be dropped at 5th floor, it will not go till the end and then start from bottom to drop you at 3rd floor. Though it will go till the last requested level, it will drop you on the way back.
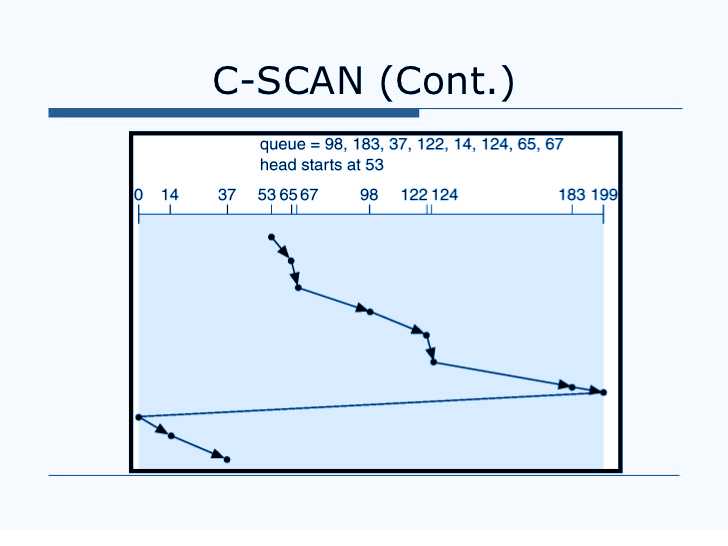
• C-Scan Disk Scheduling
Almost like the scan disk scheduling, in C-scan disk scheduling, there is no start and end time. The CPU keeps on functioning in a circular motion. Thus the CPU keeps on performing in a loop where the ending point of one list is the starting point of another. This is because while the CPU is performing is one schedule a user might enter some new data and then the process needs to restart. It is used for carrying out the same procedures repetitively.
• C-Look Disk Scheduling
It is an improvised version of C-Scan Scheduling, where the process does not function for the entire end to end. But, it considers the latest request made if it is in the same direction in which scan is being done. Though it goes to the other end, it doesn’t go till the end of the process, and only till the last required end.
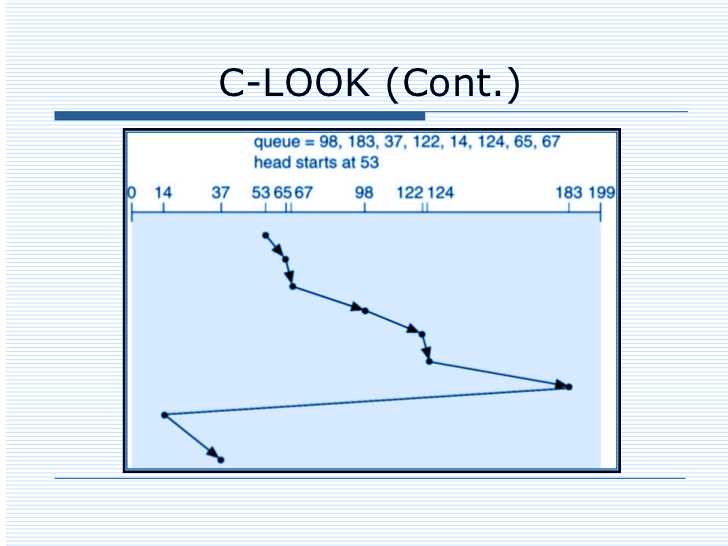
A lot of data is entered into the computer simultaneously, and it starts forming a queue on the disk. When this queue starts going long, the seek time also starts increasing, which in turn impacts the performance of the system. However, this is not a desirable scenario, and therefore disk scheduling is crucial as it controls the seek time and enhances the system’s performance level.